July 10, 2025
Context Engineering, Memory and Agentic Browsers
The AI field is known for coming up with new fancy terms to make it sound all sophisticated.
One of the recent trend that has caught up off late is Context Engineering, Memory and Agentic Browsers.
The term Context Engineering, ideally was started by Dex Horthy at Humanlayer via his “12 Factors Agents” and not Tobi from Shopify or Karpathy as many seems to misleadingly attribute to in their blogs and talks.
If you are someone who is working or interested in Agentic AI, would recommend going through “12 Factors Agents” as my take on how to build Agentic AI products is very similar after having spent some time writing code last couple of years in this area. Plus Dex appears a no fluff guy, a trait I rarely find in most ppl around me last few years in an era when “influencing” has become most’s core value.
Context Engineering
Every Useful Agentic App is basically a function of two things: Context Engineering and Reliability Engineering. That’s all.
Good Context leads to better Reliability. Bad Context leads to unreliable LLM app. However, you can also have a perfect context and yet less reliable LLM App. That is why both exist together for a production LLM App and working only on one won’t lead to adoptable AI LLM Products.
I will write about Reliability Engineering in a separate post, however one of the best ways to aim for reliability out of your LLM apps is by building with Schema First Design Principle. That leads to more Structured Input and Output which leads to easier validation and trigger point for Human in the Loop UX. All design patterns that help in more deterministic reliability from your LLM product.
In fact, IMO, Post 2025, most Software Development Engineer(SDE) profession would largely be Agents Design Engineer (ADE) where two key areas of skills would be Context Engineering and Reliability Engineering.
Quite a few ppl conflate Context Engineering as a new term for Prompt Engineering. While there is a section of ppl that conflates it with Memory.
That’s a wrong thinking.
Context is about everything you need to provide to LLM to better understand the current environment State it has been presented with. It includes external context via RAG, in-context via System Prompts and Memory- facts that you want to store about the past Environment States.
There are already quite a few blogs written by ppl which get this correct and Drew Breunig has even more great details to read on issues with wrong context.
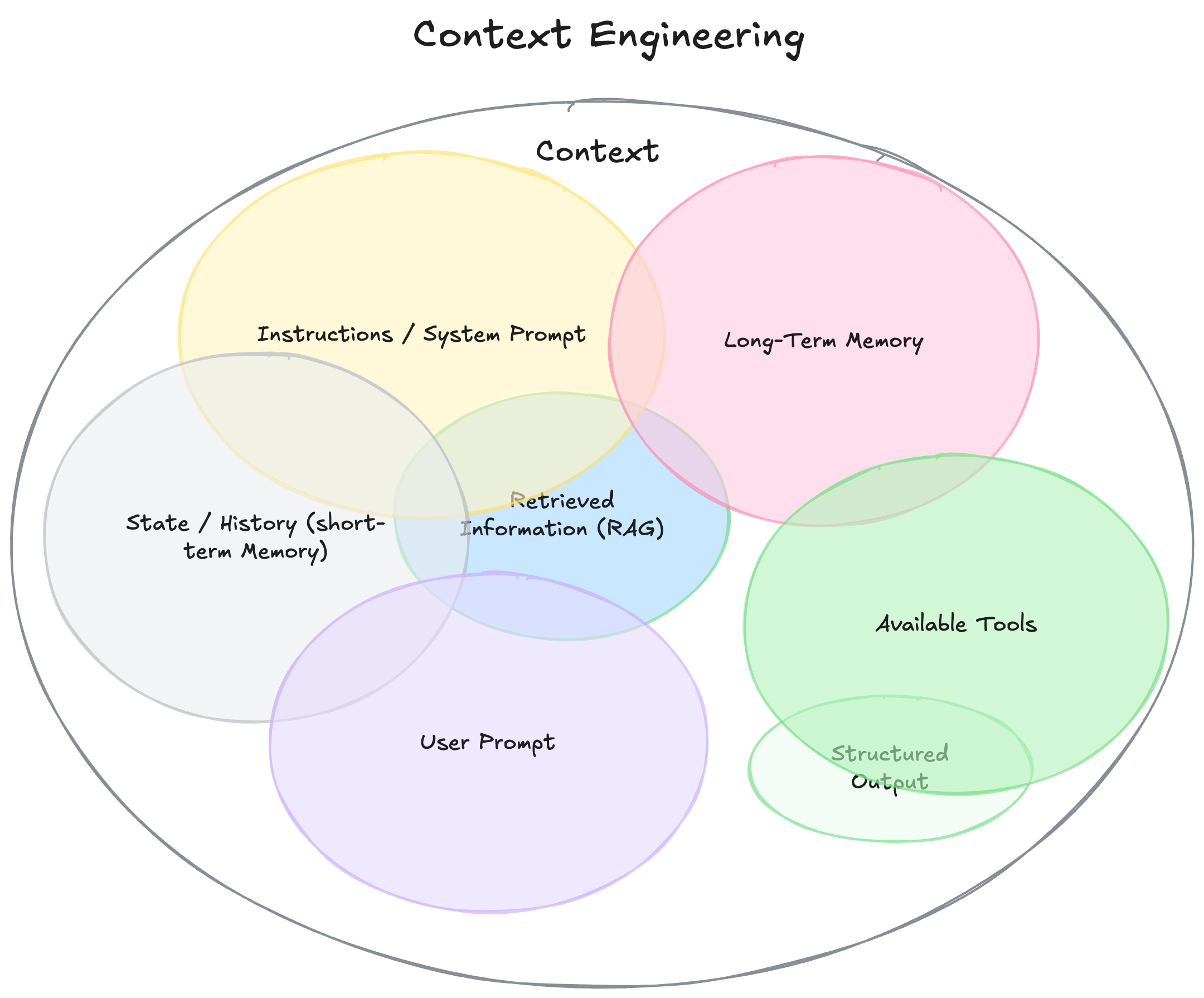
This brings to the topic of Memory
Memory
Memory has become quite discussed topic last few months, primarily in my opinion driven by Sam Altman’s tweet on ChatGPT Memory. This has led to as usual a flurry of developer and VC folks in the Valley jumping the gun on Memory as the MOAT for GenAI Apps. Silicon Valley is (in)famous for herd style thinking on various topics in tech/society so I wasn’t surprised how fervent the discussion on Memory became that many VCs started investing in Memory as Infra play.
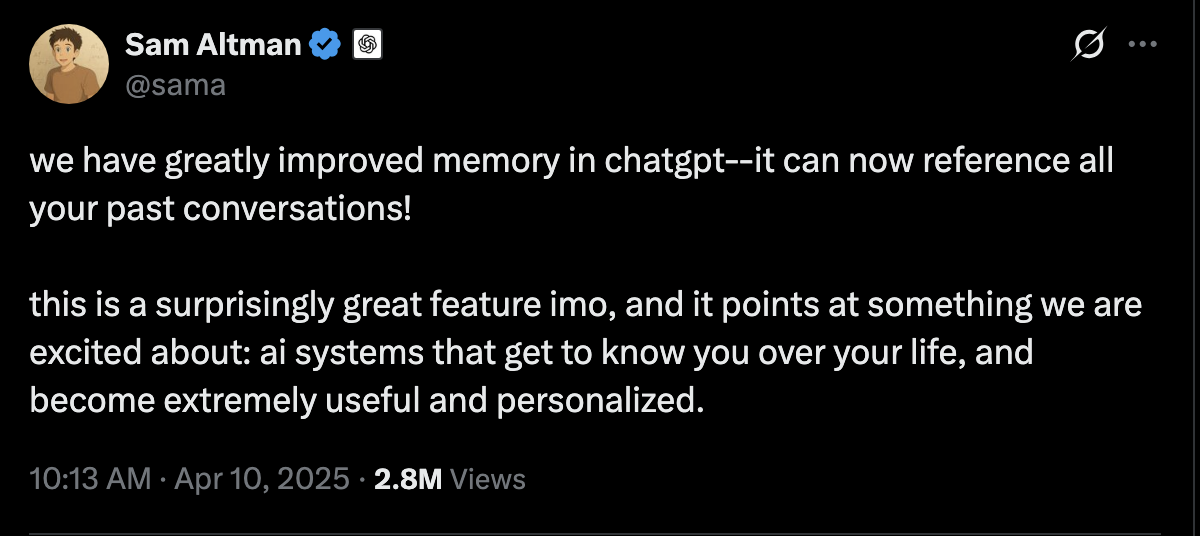
Sama, as with most things with him, isn’t optimizing on Intellectual Honesty but whatever sells his pitch.
Memory is not a Moat and more so not even useful at all for horizontal LLM App.
It’s mainly useful and could even become a moat for Vertical consumer or Enterprise (to less extent) LLM Apps.
Why is that?
Memory is useful for Vertical Consumer and Enterprise LLM Apps. .
It’s not a moat at all and not even that important for horizontal consumer or enterprise LLM app like ChatGPT, Gemini, Perplexity etc.
Reason because ChatGPT and other similar horizontal LLM Apps are like your Uber and Lyft of this decade. When you were using Uber, it does’t take much time for you to switch to Lyft if the price was cheaper. There was no moat for a user.
Similarly, when a user goes to chatGPT, it normally goes for new queries and new query has very less relevance to past queries. Every session is a new session on new question. In a pure QnA kind of LLM horizontal use case, memory doesn’t matter to a user as it’s not going to make the exp better for that particular query.
However now imagine you are building a vertical consumer app lets say in Travel space driven by LLM. Now Memory is super important because every needs of a user can be personalized across sessions. The kind of place they like, what happened in their past trip, any specific criteria of flight or hotel they have. All these persists across the session so this is where Memory plays a role.
Or imagine you have a Personal AI Medical Doctor, that has access to all your medical tests results(labs, imaging tests, doctor notes, medicine prescriptions) and it needs to maintain a memory of everything going on with respect to your health over a period of months and years for it to better diagnose your health. Memory, part of Context Engineering is the main USP there.
So that means Memory plays a role, but in a small niche area of LLM apps (Vertical plays) than the overarching belief that it is a universal moat.
This brings to last segue:
Agentic Browsers
Agentic Browsers or AI Browsers is becoming the next GenAI product war. Two players, Perplexity (with Comet) and OpenAI are mainly releasing their Agentic Browser to so called compete with Google Chromes of the world.
THIS IS A BAD IDEA!!
Dunking on Google has become the favorite pastime for everyone in Valley nowdays, while Google is slowly racing ahead in LLM Models and Cloud APIs. However, their consumer side Agentic products is still largely absent.
The fundamental belief in my opinion, OpenAI and Perplexity of the world are trying to go after is two fold:
-
Ppl love a great personalized product
-
Most humans spend bulk of their computer time on a web browser.
While both the beliefs are true, the understanding of human behavior is flawed which has led to flurry of bad strategy of building an Agentic Browser as a “consumer need”.
Most ppl as a consumer (non work behavior) don’t use browsers for automation work or aren’t seeking a desire to automate their tasks they do on a browser.
While everyone loves a good personalization and hates irrelevant distractions, human tendency is to not have it in one “all encompassing” app that understands and “watches” their browsing activity across all the verticals (shopping, entertainment, search, porn). This is one area where “Everything App” like concept doesn’t work.
The nuance around human behavior is also misunderstood.
Most ppl don’t actually care much what Google captures about them via Chrome (almost everything). As even though Google knows what all you browsed and watched, ppl don’t have this at the top of their mind when they use Chrome or Safari from Apple.
However, the moment you tell them “we have an AI native browser because we will help it automate some of your tasks or build great personalization as your personal assistant”, Human behavior will be not to use it because now they have been *unknowingly forewarned* by you what is the specific USP of this browser (be more personalized to you driven by AI). And now suddenly they won’t use it as no AI works without having access to data.
This nuance quirk in human behavior is what Perplexity CEO, Sam Altman miss and neither anyone who is working on building an AI native browser.
And this is why all Agentic Browser products will IMO, fail to get adoption by consumers and is a bad thing to invest or build.
None of them will cause even a minor dent in Google Chrome.
In fact, the only place where anything agentic will actually work for a browser is going to be Chrome itself. Because ppl have already given up their privacy to Chrome for years. Even there, quite a few would think twice in allowing AI in their browsing activity, yet, it’s the only best place where some agentic workflow in browser that could be added.
So while next few weeks and months you will start hearing a barrage of narratives by folks in Valley who have unfortuantely grabbed a bugle for an audience, - on how amazing and magical this Agentic Browser from so and so company is (mainly OpenAI, Perplexity) and the upcoming doom of Chrome as a browser, - just take a deep seat and relax.
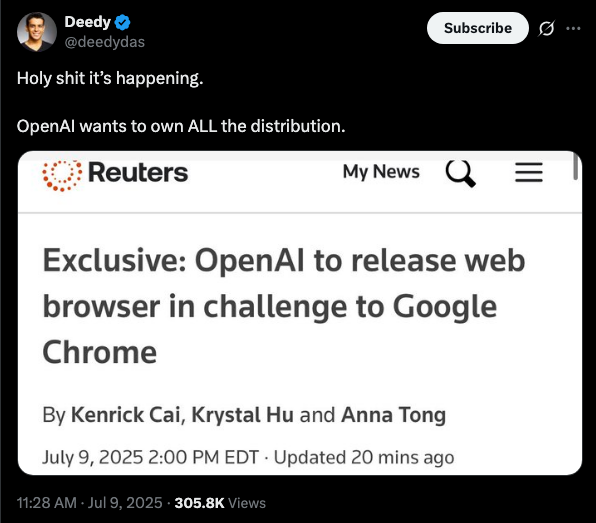
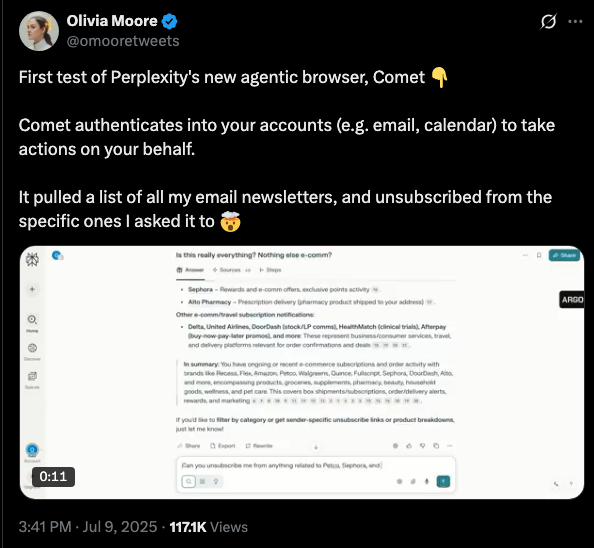
None of them would succeed and all will be shut down eventually for lack of adoption by consumers.
Products are driven and adopted by humans actions. And human actions are largely driven by human behavior. If you don’t get a good sense of human behavior understanding, most consumer products won’t work and will eventually fail.